Seja  um grafo finito e conexo. O leitor não familiarizado com as nomenclaturas elementares da Teoria dos Grafos pode consultar estas notas.
um grafo finito e conexo. O leitor não familiarizado com as nomenclaturas elementares da Teoria dos Grafos pode consultar estas notas.
Um passeio aleatório em  é uma sequência
é uma sequência  de vértices de
de vértices de  de modo que
de modo que 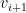 é escolhido uniformemente em
é escolhido uniformemente em  , a vizinhança de
, a vizinhança de  , para todo
, para todo 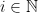 . Dizendo de outro modo, é uma cadeia de Markov
. Dizendo de outro modo, é uma cadeia de Markov  homogênea com como conjunto de estados e
homogênea com como conjunto de estados e
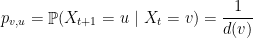
para todo  e todo
e todo  , onde
, onde 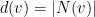 é o {grau do vértice}
é o {grau do vértice}  .
.
Se 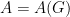 é a matriz de adjacências de , isto é
é a matriz de adjacências de , isto é  com
com 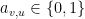 e
e  sse e só se
sse e só se  é aresta, e
é aresta, e  é a matriz diagonal
é a matriz diagonal 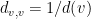 então a matriz de transições do passeio aleatório em
então a matriz de transições do passeio aleatório em  é
é

Exemplo 129 Seja o grafo sobre o conjunto de vértice 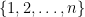 com todas as
com todas as  arestas, chamado de grafo completo, e consideremos um passeio aleatório em , assim
arestas, chamado de grafo completo, e consideremos um passeio aleatório em , assim

e a matriz de transição é  .
.
Nesse caso, o número esperado de passos para atingir a partir de  é
é  . De fato, a probabilidade de atingir em 1 passo é
. De fato, a probabilidade de atingir em 1 passo é 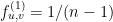 , a probabilidade de atingir em 2 passos é
, a probabilidade de atingir em 2 passos é  , em 3 passos
, em 3 passos  , e assim por diante.
, e assim por diante.
O número esperado de passos é
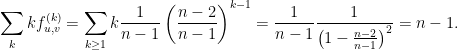
O número esperado de passos para visitar todos os vértices do grafo pode ser estimado da seguinte forma. Seja 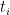 o instante em que pela primeira vez temos exatamente
o instante em que pela primeira vez temos exatamente  vértices visitados, portanto,
vértices visitados, portanto,  é uma variável aleatória geométrica que conta o número de passos enquanto espera-se para conhecer um novo vértice, evento que ocorre com probabilidade
é uma variável aleatória geométrica que conta o número de passos enquanto espera-se para conhecer um novo vértice, evento que ocorre com probabilidade 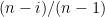 , logo
, logo 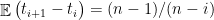 e
e 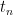 é o número de passos até visitar todos os vértices
é o número de passos até visitar todos os vértices
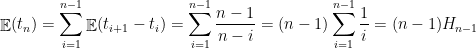
onde  denota o
denota o  -ésimo número harmônico,
-ésimo número harmônico,  , onde
, onde  é a constante de Euler–Mascheroni.
é a constante de Euler–Mascheroni.
Um passeio aleatório num grafo conexo é uma cadeia de Markov irredutível e em certos casos aperiódica. O próximo resultado caracteriza tais passeios aleatórios aperiódicos.
Teorema 22 Se é conexo com pelo menos dois vértices então um passeio aleatório em define uma cadeia de Markov irredutível. Ainda, tal cadeia de Markov é periódica se e só se é bipartido.
Demonstração: Se é conexo então para dois vértices e quaisquer que estão a distância  vale
vale  . Como é conexo a distância entre quaisquer dois vértices é algum
. Como é conexo a distância entre quaisquer dois vértices é algum 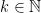 , portanto a cadeia de Markov definida pelo passeio aleatório é irredutível.
, portanto a cadeia de Markov definida pelo passeio aleatório é irredutível.
Seja um grafo conexo e bipartido com bipartição 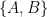 . Então, todos os passeios de para têm a mesma paridade no número de arestas, para o caso
. Então, todos os passeios de para têm a mesma paridade no número de arestas, para o caso  ou
ou  e ímpar caso
e ímpar caso 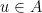 e
e 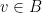 ou
ou  e
e 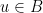 . Logo
. Logo
- se ou então exceto quando é ímpar,
- se e , ou e , então exceto quando é par.
Portanto a cadeia tem período  .
.
Agora, suponhamos não-bipartido, então contém um circuito de comprimento ímpar  . Tomemos
. Tomemos  um passeio de
um passeio de  a
a  , vértices que distam
, vértices que distam  em , com o menor número de arestas. Um passeio de para com
em , com o menor número de arestas. Um passeio de para com  arestas existe para todo
arestas existe para todo  , basta repetir
, basta repetir  vezes alguma aresta do passeio . Como é conexo existe um passeio de algum vértice de até algum vértice de , portanto, podemos usar as arestas de para obter passeios de para que têm a paridade oposta a de . Logo,
vezes alguma aresta do passeio . Como é conexo existe um passeio de algum vértice de até algum vértice de , portanto, podemos usar as arestas de para obter passeios de para que têm a paridade oposta a de . Logo,  para todo
para todo  suficientemente grande, ou seja, a cadeia é aperiódica.
suficientemente grande, ou seja, a cadeia é aperiódica. 
Corolario 23 Se  é conexo, não-bipartido e com pelo menos dois vértices então a cadeia de Markov dada por um passeio aleatório em admite um vetor estacionário. Ademais, a distribuição estacionária é única e dada por
é conexo, não-bipartido e com pelo menos dois vértices então a cadeia de Markov dada por um passeio aleatório em admite um vetor estacionário. Ademais, a distribuição estacionária é única e dada por

Demonstração: A cadeia é irredutível e aperiódica, portanto admite um único vetor estacionário pelo teorema 20. Agora, basta verificar que (65) é estacionário.
A soma dos graus dos vértices de um grafo é  , logo
, logo  . Resta verificar que
. Resta verificar que  , onde
, onde  é a matriz de transição, mas
é a matriz de transição, mas
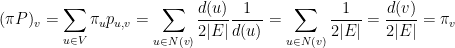
portanto, o vetor dado em (65) é o vetor estacionário. 
Observação 10 Se é bipartido então podemos contornar essa propriedade indesejada (no sentido do corolário acima) acrescentando laços aos vértices do grafo com probabilidade de transição  (ou seja,
(ou seja,  ) e dividir por 2 a probabilidade das outras arestas, ou seja, se é a matriz de transição da cadeia no grafo original, a nova matriz de transição é
) e dividir por 2 a probabilidade das outras arestas, ou seja, se é a matriz de transição da cadeia no grafo original, a nova matriz de transição é
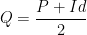
onde  é a matriz identidade
é a matriz identidade  . Essa transformação apenas “reduz a velocidade” do passeio.
. Essa transformação apenas “reduz a velocidade” do passeio.
Exemplo 130 De volta ao grafo completo do exemplo 129, vamos usar a estratégia de acrescentar laço e o número esperado de passos até um passeio aleatório passar por todos os vértices de . Seja a matriz de transição da cadeia de Markov do passeio em e consideremos a modificação acima, acrescentando um laço em cada vértice ficamos com a matriz de transição do novo passeio

Seja  o número de passos para o passeio definido por
o número de passos para o passeio definido por  visitar todos os vértice e
visitar todos os vértice e 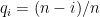 a probabilidade de visitar um vértice novo se outros vértices já foram visitados, então o número esperado de passos até o passeio visitar o
a probabilidade de visitar um vértice novo se outros vértices já foram visitados, então o número esperado de passos até o passeio visitar o  -ésimo vértice é
-ésimo vértice é 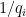 . Assim,
. Assim,
 conexidade em grafos
conexidade em grafos
O problema da conexidade em grafos é: dado um grafo e dois vértices  em decidir se há um passeio entre esses dois vértices. Esse problema pode ser resolvido em tempo linear no tamanho do grafo,
em decidir se há um passeio entre esses dois vértices. Esse problema pode ser resolvido em tempo linear no tamanho do grafo,  , e usando espaço
, e usando espaço  .
.
A pergunta que interessa nesse caso é se o problema pode ser resolvido usando espaço logarítmico. Essa pergunta foi respondida afirmativamente em [Reingold, Undirected connectivity in log-space, J. ACM 58, 2008], até então o único progresso significativo foi o algoritmo aleatorizado que apresentaremos a seguir devido a [Aleliunas, Karp, Lipton, Lovasz, Rackoff, Random walks, universal traversal sequences, and the complexity of maze problems, SFCS ’79].

Notemos que o espaço extra gasto pelo algoritmo é para manter o vértice atual e o contador de rodadas para o laço, portanto, o espaço utilizado é 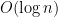 para um grafo com vértices.
para um grafo com vértices.
Se o algoritmo devolve sim então o grafo contém um passeio entre os vértices  e
e  . Agora, se o algoritmo responde não, então ou não há caminho, ou o algoritmo não foi capaz de encontrá-lo em tempo. Portanto, se não existe caminho a resposta está correta, caso contrário a resposta pode estar errada e vamos limitar a probabilidade de erro.
. Agora, se o algoritmo responde não, então ou não há caminho, ou o algoritmo não foi capaz de encontrá-lo em tempo. Portanto, se não existe caminho a resposta está correta, caso contrário a resposta pode estar errada e vamos limitar a probabilidade de erro.
Seja o tempo para um passeio aleatório no grafo visitar todos os vértices de . O tempo de cobertura de (cover time) é

Lema 24 O tempo de cobertura de um grafo conexo é no máximo  .
.
Demonstração: Tomemos um subgrafo acíclico maximal de (ou, uma árvore geradora) e consideremos um passeio  nas
nas  arestas dessa árvore de modo que cada aresta seja percorrida exatamente duas vezes, uma vez em cada direção. O tempo de cobertura de é limitado superiormente pelo tempo esperado para um passeio percorrer a sequência
arestas dessa árvore de modo que cada aresta seja percorrida exatamente duas vezes, uma vez em cada direção. O tempo de cobertura de é limitado superiormente pelo tempo esperado para um passeio percorrer a sequência  que é
que é
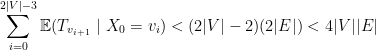
pois 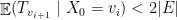 para toda aresta
para toda aresta  em . De fato, , calculando
em . De fato, , calculando  de dois modos distintos
de dois modos distintos
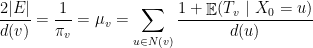
portanto, 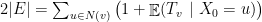 .
.
Com isso conseguimos estimar a probabilidade de erro da seguinte maneira. Seja um grafo e e dois vértices de que são ligados por um passeio. O algoritmo erra se em 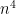 rodadas não consegue achar um caminho em . Denotemos por
rodadas não consegue achar um caminho em . Denotemos por 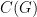 o tempo de cobertura de
o tempo de cobertura de
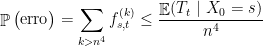
pela desigualdade de Markov, logo

— Passeio aleatório em grafos regulares —
Um grafo é regular se todos os vértices têm o mesmo grau. Nesse caso temos um bom tanto de informação que podemos retirar da matriz de transição que é duplamente estocástica (veja o exercício 103). A começar, que essa matriz é simétrica, portanto, todos os seus autovalores são reais, ademais, o Teorema Espectral garante a existência de uma família ortonormal de autovetores, tantos quanto é a dimensão da matriz. Um passeio aleatório num grafo regular converge para a distribuição uniforme (exercício 103) e nesta seção mostraremos que a velocidade dessa convergência é ditada pelo segundo maior autovalor da matriz de transição.
Um grafo é  -regular,
-regular, 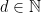 , se todos os vértice de têm grau . No que segue, vamos assumir que todo grafo é sobre
, se todos os vértice de têm grau . No que segue, vamos assumir que todo grafo é sobre  , é conexo e -regular.
, é conexo e -regular.
Nesse caso, a matriz de transição de um passeio em é

, para a martiz de adjacências. A matriz é simétrica, portanto, seus autovalores são reais. Sejam
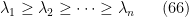
os autovalores de . Do Teorema de Perron–Frobenius temos que se é conexo então
 ;
;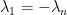 se e somente se é bipartido.
se e somente se é bipartido.
Não é difícil constatar que o vetor  com todas as coordenadas iguais a
com todas as coordenadas iguais a 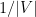 é um autovetor de associado ao autovalor
é um autovetor de associado ao autovalor  , ou seja,
, ou seja, 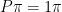 e como é simétrica
e como é simétrica
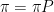
que, em outras palavras, quer dizer que a distribuição uniforme sobre é a distribuição estacionária do passeio aleatório em .
Ainda, se é tal que 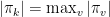 então
então

ou seja, 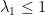 , portanto
, portanto  .
.
Seja um grafo conexo, não-bipartido, -regular e com vértices. Fixemos

e 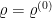 uma distribuição inicial sobre , seja
uma distribuição inicial sobre , seja  a distribuição de probabilidade sobre os vértices de no instante
a distribuição de probabilidade sobre os vértices de no instante 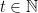 . Vamos mostrar que
. Vamos mostrar que  converge para
converge para  com velocidade controlada por
com velocidade controlada por  .
.
Seja 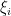 ,
, 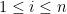 , uma base ortonormal de autovetores de , de modo que é autovetor associado a
, uma base ortonormal de autovetores de , de modo que é autovetor associado a  . Notemos que
. Notemos que 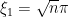 . Se
. Se 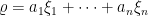 então
então 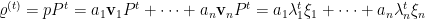 e
e

donde segue que

e como  temos converge para
temos converge para  quando
quando 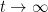 , logo é igual a , pelo teorema 20.
, logo é igual a , pelo teorema 20.
Com isso, provamos
Lema 25 Sejam um grafo com vértices, conexo, -regular e não-bipartido,  a matriz de transição de um passeio aleatório em e
a matriz de transição de um passeio aleatório em e

Então para todo vetor de probabilidades  e todo
e todo
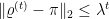
onde  é o vetor estacionário do passeio aleatório.
é o vetor estacionário do passeio aleatório.
Exercício 108 Seja  um vetor, então
um vetor, então  é uma norma dada por
é uma norma dada por

Prove que  para todo
para todo  .
.
Teorema 26 Seja  um passeio aleatório num grafo com vértices, conexo, -regular e não-bipartido e com segundo maior autovalor . Então, para todo
um passeio aleatório num grafo com vértices, conexo, -regular e não-bipartido e com segundo maior autovalor . Então, para todo 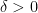 existe
existe  tal que
tal que
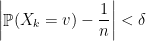
para todo vértice .
Demonstração: Seja como no enunciado. Vamos mostrar que
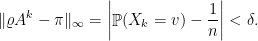
Seja  uma distribuição inicial qualquer, então a distribuição de
uma distribuição inicial qualquer, então a distribuição de 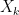 é dada pelo vetor
é dada pelo vetor  ,
,

em que é a matriz de transição do passeio aleatório.
Pelo lema 25 e exercício acima

portanto, se  então
então  .
.
Exercício 109 Verifique se vale o resultado anterior para bipartido, conexo e -regular com o passeio aleatório dado por  , onde .
, onde .
Exercício 110 Sejam um grafo com vértices, conexo, -regular e 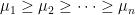 os autovalores da matriz de adjacências de . Consideremos as matrizes estocásticas e cujos autovalores são, respectivamente,
os autovalores da matriz de adjacências de . Consideremos as matrizes estocásticas e cujos autovalores são, respectivamente, 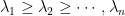 e
e  . Prove que
. Prove que

para todo inteiro .
Exercício 111 Sejam um grafo com vértices,  arestas e os autovalores da matriz de adjacências de . Prove que
arestas e os autovalores da matriz de adjacências de . Prove que

(Segestão:  e a soma da diagonal princial da matriz
e a soma da diagonal princial da matriz 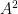 e
e  é diagonalizável.)
é diagonalizável.)
— Passeios aleatórios em grafos expansores —
Da discussão anterior podemos concluir que quanto menor for o segundo autovalor de um grafo, que passamos a denotar por  , mais rápido um passeio aleatório converge para a distribuição uniforme, entretanto não pode ser arbitrariamente pequeno. De (68) temos
, mais rápido um passeio aleatório converge para a distribuição uniforme, entretanto não pode ser arbitrariamente pequeno. De (68) temos

portanto, no caso -regular  .
.
No que segue, 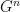 é um grafo com vértices, conexo e -regular para fixo. Dizemos que é um grafo
é um grafo com vértices, conexo e -regular para fixo. Dizemos que é um grafo  -expansor se
-expansor se 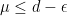 .
.
Seja um subconjunto de vértices de . Denotamos por  o subconjunto dos vértices de
o subconjunto dos vértices de  que são adjacente a algum vértice de . Dizemos que é
que são adjacente a algum vértice de . Dizemos que é  -vértice expansor separa todo com
-vértice expansor separa todo com  vale que
vale que 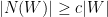 , daí vem o expansor. Essas definições são equivalentes no seguinte sentido: se é -expansor então é
, daí vem o expansor. Essas definições são equivalentes no seguinte sentido: se é -expansor então é  -vértice-expansor. Por outro lado, se é -vértice-expansor então é
-vértice-expansor. Por outro lado, se é -vértice-expansor então é  -expansor. Logo, grafos expansores são caracterizados combinatorialmente por possuir alta conexidade, que é equivalente a dizer que a distância espectral (diferença
-expansor. Logo, grafos expansores são caracterizados combinatorialmente por possuir alta conexidade, que é equivalente a dizer que a distância espectral (diferença  entre os dois maiores autovalores da matriz de adjacências do grafo) é grande.
entre os dois maiores autovalores da matriz de adjacências do grafo) é grande.
Grafo expansores esparsos são objetos aparentemente contraditórios, mas a existência desses grafos segue de métodos probabilísticos usuais, como mostrou Pinsker em 1973 que quase todo grafo -regular, 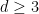 , é expansor. Embora abundantes, a construção explícita desses grafos não é simples; de fato, em geral a construção mas a prova da expansão usa ferramentas profundas e complexas da matemática. Sortear um grafo e testar se é expansor é inviável, o sorteio usa muitos bits aleatórios (uma das principais aplicações desses grafos que veremos aqui é o uso para economizar bits aleatórios em algoritmos aleatorizados) e o problema de decisão está em
, é expansor. Embora abundantes, a construção explícita desses grafos não é simples; de fato, em geral a construção mas a prova da expansão usa ferramentas profundas e complexas da matemática. Sortear um grafo e testar se é expansor é inviável, o sorteio usa muitos bits aleatórios (uma das principais aplicações desses grafos que veremos aqui é o uso para economizar bits aleatórios em algoritmos aleatorizados) e o problema de decisão está em  .
.
No que segue vamos assumir a possibilidade de construir explicitamente grafos expansores tais que dados um vértice  e
e  o vértice
o vértice  pode ser determinado em espaço logarítmico. Para as construções explícitas o leitor pode consultar este documento O nosso interesse é no uso desses grafos para desaleatorização em BPP que segue a seguinte estratégia. Suponha que temos um algoritmo que decide
pode ser determinado em espaço logarítmico. Para as construções explícitas o leitor pode consultar este documento O nosso interesse é no uso desses grafos para desaleatorização em BPP que segue a seguinte estratégia. Suponha que temos um algoritmo que decide 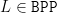 com probabilidade de erro menor que usando bits aleatórios para entradas de tamanho fixo. Então, podemos construir um algoritmo que decide a mesma linguagem com probabilidade de erro menor que
com probabilidade de erro menor que usando bits aleatórios para entradas de tamanho fixo. Então, podemos construir um algoritmo que decide a mesma linguagem com probabilidade de erro menor que  usando
usando 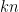 bits tomando rodadas independentes do algoritmo. Agora, suponha que temos um grafo expansor 3-regular
bits tomando rodadas independentes do algoritmo. Agora, suponha que temos um grafo expansor 3-regular  vértices. Um gerador pseudoaleatório consiste em determinar um vértice desse grafo uniformemente, de modo que temos os bits aleatórios necessários para uma rodada do algoritmo. Para determinar um desses vértices usamos o lema 25, que diz que é suficiente começamos um passeio aleatório de comprimento
vértices. Um gerador pseudoaleatório consiste em determinar um vértice desse grafo uniformemente, de modo que temos os bits aleatórios necessários para uma rodada do algoritmo. Para determinar um desses vértices usamos o lema 25, que diz que é suficiente começamos um passeio aleatório de comprimento  , cada passo do passeio precisa de 2 bits genuinamente aleatórios. Como o algoritmo é executado vezes, o número de bits aleatórios usados é
, cada passo do passeio precisa de 2 bits genuinamente aleatórios. Como o algoritmo é executado vezes, o número de bits aleatórios usados é 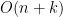 .
.
Antes de expormos formalmente a idéia acima chamamo a atenção para um resultado conhecido estreitamente relacionado com os resultados discutidos nessa seção.
Expander mixing lemma
É sabido que se  então a distribuição de arestas entre
então a distribuição de arestas entre  e
e  em satisfaz
em satisfaz
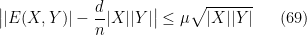
Esboço de demonstração: Seja , , uma base ortonormal de autovetores de . Sejam 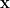 e
e  os vetores (linha) característicos de e , respectivamente. Então
os vetores (linha) característicos de e , respectivamente. Então 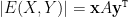 , onde
, onde  denota o transposto. Escrevendo na base de autovetores
denota o transposto. Escrevendo na base de autovetores 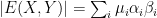 , onde
, onde 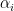 e
e  são os produtos escalares
são os produtos escalares 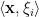 e
e  , respectivamente. O resultado segue de
, respectivamente. O resultado segue de 
Portanto,  pequeno garante um distribuição de arestas como num grafo aleatório com densidade de arestas
pequeno garante um distribuição de arestas como num grafo aleatório com densidade de arestas 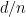 . Grafos com pequeno são ditos pseudoaleatórios . Linial e Bilu provaram uma recíproca desse resultado, se 69 vale para algum
. Grafos com pequeno são ditos pseudoaleatórios . Linial e Bilu provaram uma recíproca desse resultado, se 69 vale para algum  então segundo maior autovalor de
então segundo maior autovalor de  é
é 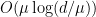 .
.
De (69) temos
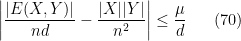
ou seja, a probabilidade de sortear um par de vértices e cair em  é próxima a probabilidade de sortear uma aresta e cair em
é próxima a probabilidade de sortear uma aresta e cair em  . Escrevendo de ouro modo, consideremos a vizinhança de cada vértice de indexada por
. Escrevendo de ouro modo, consideremos a vizinhança de cada vértice de indexada por  e denotemos por o -ésimo vizinho do vértice de acordo com essa indexação. Assim, a equação (69) pode ser interpretada como
e denotemos por o -ésimo vizinho do vértice de acordo com essa indexação. Assim, a equação (69) pode ser interpretada como
![\displaystyle \Big| \mathop{\mathbb P}_{(x,i)\in_\mathrm{R}V\times [d]}\big( [x\in X]\cap [v_i(x)\in Y]\big) - \mathop{\mathbb P}_{(x,y)\in_\mathrm{R}X\times Y}\big([x\in X]\cap[y\in Y]) \Big| \leq \frac {\mu}d.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5CBig%7C+%5Cmathop%7B%5Cmathbb+P%7D_%7B%28x%2Ci%29%5Cin_%5Cmathrm%7BR%7DV%5Ctimes+%5Bd%5D%7D%5Cbig%28+%5Bx%5Cin+X%5D%5Ccap+%5Bv_i%28x%29%5Cin+Y%5D%5Cbig%29+-+%5Cmathop%7B%5Cmathbb+P%7D_%7B%28x%2Cy%29%5Cin_%5Cmathrm%7BR%7DX%5Ctimes+Y%7D%5Cbig%28%5Bx%5Cin+X%5D%5Ccap%5By%5Cin+Y%5D%29+%5CBig%7C+%5Cleq+%5Cfrac+%7B%5Cmu%7Dd.+&bg=ffffff&fg=000000&s=0&c=20201002)
— Passeio aleatório na Web: O Google Page Rank —
“To test the utility of PageRank for search, we built a web search engine called Google” Page, Brin, Motwani, Winograd, The PageRank Citation Ranking: Bringing Order to the Web.
O grafo web é um grafo dirigido definido pelas páginas web e as ligações (links ou hyperlinks) entre as páginas. Conhecer a estrutura desse grafo é importante para o desenvolvimento de algoritmos eficientes para a web, por exemplo.

Um marco no projeto e desenvolvimento desses algoritmos é o algoritmo PageRank [Page, Brin, Motwani, Winograd, The PageRank Citation Ranking: Bringing Order to the Web] desenvolvido como parte da ferramenta de busca na web batizada Google pelos fundadores da empresa com mesmo nome.
O PageRank é um algoritmo para classificação (ranking) de páginas na web. A idéia que o motivou é modelar a importância relativa de uma página de modo que uma busca resulte em resultados com relevância. A própria empresa explica a idéia da seguinte maneira:
“O coração do nosso software é o PageRank(TM), um sistema para dar notas para páginas na web, desenvolvido pelos nossos fundadores Larry Page e Sergey Brin na Universidade de Stanford. E enquanto nós temos dúzias de engenheiros trabalhando para melhorar todos os aspectos do Google no dia a dia, PageRank continua a ser a base para todas nossas ferramentas de busca na web.
Explicações sobre o PageRank
A classificação das páginas (PageRank) confia na natureza excepcionalmente democrática da Web, usando sua vasta estrutura de links como um indicador do valor de uma página individual. Essencialmente, o Google interpreta um link da página A para a página B como um voto da página A para a página B. Mas o Google olha além do volume de votos, ou links, que uma página recebe; analisa também a página que dá o voto. Os votos dados por páginas “importantes” pesam mais e ajudam a tornar outras páginas “importantes.””
(http://www.google.com.br/why_use.html)
Assim, uma página tem uma classificação alta se é referenciada por páginas com classificação alta.
O que nos interessa no momento é que o modelo adotado no PageRank pode ser interpretado como um passeio aleatório no grafo web: um internauta absorto, começa a navegar na web a partir de uma página qualquer, e segue a navegação por um dos links da página atual escolhido uniformemente; depois de muito tempo nessa tarefa as páginas começam a repetir e o internauta entediado pára o processo e recomeça-o a partir de alguma outra página.
O modelo simplificado do PageRank é descrito da seguinte maneira. Seja o grafo da web, ou seja, é o conjuntos formado pelas páginas web, as quais serão consideradas sem perda de generalidade  , e
, e  se na página
se na página  há um link para a página
há um link para a página  . Denotamos por
. Denotamos por 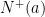 o conjunto dos vértices tais que
o conjunto dos vértices tais que  é uma aresta de , e por
é uma aresta de , e por  denotamos o conjunto dos vértices tais que
denotamos o conjunto dos vértices tais que  é uma aresta de . No grafo web da figura 0
é uma aresta de . No grafo web da figura 0  e
e  .
.
A classificação é dada por um vetor  onde
onde  é a classificação da página e satisfaz
é a classificação da página e satisfaz
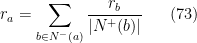
ou seja, se aponta para então contribui com  de sua relevância para a relevância de . Seja a matriz
de sua relevância para a relevância de . Seja a matriz

então de (73)
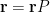
ou seja, é um autovetor à esquerda de . No grafo web da figura 0 está descrita a matriz de transição para aquele grafo.
Se for uma matriz estocástica então o vetor é um vetor estacionário e dessa forma, pode ser calculado escolhendo uma distribuição inicial 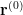 e fazendo
e fazendo  . Como vimos, sob certas hipóteses
. Como vimos, sob certas hipóteses  converge para . Esse método, conhecido como método das potências, é usado há muito tempo para calcular autovetores associado ao maior autovalor. Entretanto, na atual situação não sabemos se o vetor converge pois não temos garantia que a matriz seja irredutível (garante , portanto convergência) ou estocástica (garante o autovalor , portanto o método converge para o vetor estacionário).
converge para . Esse método, conhecido como método das potências, é usado há muito tempo para calcular autovetores associado ao maior autovalor. Entretanto, na atual situação não sabemos se o vetor converge pois não temos garantia que a matriz seja irredutível (garante , portanto convergência) ou estocástica (garante o autovalor , portanto o método converge para o vetor estacionário).
Exemplo 131 Por exemplo, para

e  temos
temos  , No caso de um circuito dirigido, um vetor inicial pode não convergir.
, No caso de um circuito dirigido, um vetor inicial pode não convergir.
No exemplo da figura 0 abaixo a matriz não é estocástica.

Os vértices sem arestas que saem, ou seja os vértices tais que  são chamados de pendentes (dangling) e por causa deles a matriz não é estocástica. No exemplo da figura 0 o vértice
são chamados de pendentes (dangling) e por causa deles a matriz não é estocástica. No exemplo da figura 0 o vértice 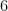 é pendente. Na web de fato há vários vértices pendentes, por exemplo, os documentos em pdf disponíveis em páginas web são vértices pendentes do grafo.
é pendente. Na web de fato há vários vértices pendentes, por exemplo, os documentos em pdf disponíveis em páginas web são vértices pendentes do grafo.
Seja o número de vértices em . Definimos uma matriz auxiliar pondo para cada vértice pendente , o que corresponde a uma página sem links, a linha com entradas 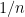 e tomamos
e tomamos
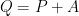
isso significa que um passeio aleatório que chega numa página sem saída continua em qualquer outra página com igual probabilidade.
A matriz é estocástica. A matriz referente a matriz da figura 0 é dada a seguir na figura 0 ao lado do grafo web que corresponde à modificação no grafo que reflete a modificação na matriz . No grafo da figura 0 as arestas tracejadas são as arestas incluídas e correspondem à possibilidade de navegação do internauta que chega a uma página sem saída e recomeça a navegação de qualquer lugar uniformemente.

No exemplo dado na figura 0, o maior autovalor da matriz é com multiplicidade e autovetor associado 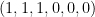 . Notemos que os vértices
. Notemos que os vértices 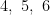 tem classificação
tem classificação  . Isso decorre do fato de não haver aresta que sai de
. Isso decorre do fato de não haver aresta que sai de 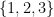 e chega em qualquer outro vértice diferente desses. Esse conjunto é chamado de sorvedouro (rank sink).
e chega em qualquer outro vértice diferente desses. Esse conjunto é chamado de sorvedouro (rank sink).
Para lidar com esses sorvedouros basta garantir que a matriz seja irredutível pois se 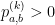 para algum , para todo
para algum , para todo 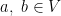 então não há sorvedouros no grafo. Para garantir uma matriz irredutível (em linguagem de Teoria dos Grafos, o grafo dirigido tem que ser fortemente conexo, caso contrário o vetor estacionário pode ter todas as coordenadas nulas fora de uma componente fortemente conexa do grafo.) tomamos
então não há sorvedouros no grafo. Para garantir uma matriz irredutível (em linguagem de Teoria dos Grafos, o grafo dirigido tem que ser fortemente conexo, caso contrário o vetor estacionário pode ter todas as coordenadas nulas fora de uma componente fortemente conexa do grafo.) tomamos 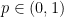 e consideramos um passeio aleatório que segue as transições de com probabilidade
e consideramos um passeio aleatório que segue as transições de com probabilidade  ou que com probabilidade
ou que com probabilidade  vai pra qualquer outra página web (como o comportamento do internauta absorto que ficou entediado), ou seja,
vai pra qualquer outra página web (como o comportamento do internauta absorto que ficou entediado), ou seja,
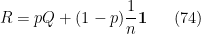
onde  é a matriz com todas as entradas iguais a . A matriz obtida de do exemplo da figura~0
é a matriz com todas as entradas iguais a . A matriz obtida de do exemplo da figura~0
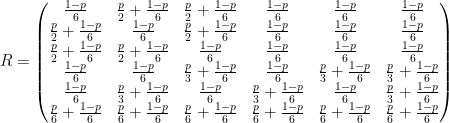
É sabido que o método iterativo para computar o vetor estacionário descrito, o método das potências, converge com velocidade 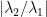 onde
onde  são os dois maiores autovalores da matriz
são os dois maiores autovalores da matriz  . Ainda, é sabido que e que
. Ainda, é sabido que e que  . O parâmetro é conhecido como fator de amortecimento (damping factor). No trabalho que originou o algoritmo os autores do PageRank estabeleceram o valor
. O parâmetro é conhecido como fator de amortecimento (damping factor). No trabalho que originou o algoritmo os autores do PageRank estabeleceram o valor 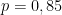 após testes. Atualmente, a Google não divulga o valor desse fator. No mesmo trabalho , os autores reportam de 50 a 100 iterações do método das potências até a condição de parada do método das potências. 0 critério tradicional de parada é da forma
após testes. Atualmente, a Google não divulga o valor desse fator. No mesmo trabalho , os autores reportam de 50 a 100 iterações do método das potências até a condição de parada do método das potências. 0 critério tradicional de parada é da forma  para uma tolerância
para uma tolerância  pequena; notemos que não é necessário conhecer as grandezas do vetor estacionário, só é preciso determinar a ordem das coordenadas, o que pode ser usado para diminuir o número de iterações. Para foi reportado que com 29 iterações
pequena; notemos que não é necessário conhecer as grandezas do vetor estacionário, só é preciso determinar a ordem das coordenadas, o que pode ser usado para diminuir o número de iterações. Para foi reportado que com 29 iterações  , e no caso de 50 a 100 iterações a tolerância é de
, e no caso de 50 a 100 iterações a tolerância é de 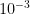 a
a 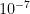 .
.
Para concluirmos esta seção vão mostrar uma alternativa para escrever essa matriz, uma vez que atordoantes 1 trilhão de páginas indexadas foi reportado pela Google em julho de 2008 . A matriz é esparsa pela natureza da web: páginas com poucos links, 52 em média , e muitos vértices pendentes, a matriz é mais densa e a matriz é positiva. A matriz pode ser escrita como 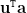 onde
onde  é o vetor com todas as entradas iguais a . De fato, pode ser qualquer vetor de probabilidades, o vetor uniforme foi a escolha original, mas atualmente sabe-se que favorece link spamming e esse parâmetro também não é divulgado pela Google. O vetor
é o vetor com todas as entradas iguais a . De fato, pode ser qualquer vetor de probabilidades, o vetor uniforme foi a escolha original, mas atualmente sabe-se que favorece link spamming e esse parâmetro também não é divulgado pela Google. O vetor  é o transposto do vetor característico dos vértices pendentes. Com essas definições
é o transposto do vetor característico dos vértices pendentes. Com essas definições

onde  , portanto só precisamos armazenar a matriz e os vetores
, portanto só precisamos armazenar a matriz e os vetores 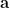 ,
,  e .
e .
Exercício 114 Mostre que a matriz é irredutível.
Exercício 115 O grafo dirigido com vértices 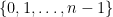 e arestas
e arestas  é um circuito dirigido com vértices. Analise o comportamento de
é um circuito dirigido com vértices. Analise o comportamento de  para com
para com  .
.





